🤝 Making TPU Model Performance Auto-optimization to work with other Agents
In the first post I walked through the TPU Model Performance Auto-optimization repo — autoresearch, LLM wiki, xprof MCP, and per-experiment branches — and showed that Claude Code with Opus 4.7 could drive a Llama 3 8B model to state-of-the-art unattended.
In the second post I covered the reliability tweaks — /loop re-injection, stop hooks, retrospectives — that made the loop run for many hours without supervision.
That post ended with a caveat I want to close now:
That said, these tweaks still didn’t get Codex or Gemini CLI to run the loop reliably — I’ll cover the fix for that in a separate post.
This is that post. And the Qwen3 8B case study update at the end of the first post is the punchline: Codex (GPT-5.5) landed at 43.2% MFU (+8.5% over MaxText), Fable 5 at 39.9% (+0.3%), and Antigravity/Gemini 3.1 Pro finally ran the loop end-to-end without hand-holding. Four different agent + harness stacks now each drive the loop autonomously. Here’s what changed.
📖 Why the original setup only worked on Claude Code
The original setup was a single big program.md file describing every step of the loop, plus a giant wiki. Claude Code with Opus 4.7 followed it. Codex and Gemini CLI didn’t.
Digging into session logs revealed the same underlying problem in a different shape than before. /loop re-injection kept the top-level instructions on top, but the loop itself was still one monolithic prompt: “read these ten pages from the wiki, look at these three previous experiments, decide on a hypothesis, generate the falsification criterion, edit the model, build the container, submit the workload, poll it, analyze the profile, write up the verdict.” Every step of that was competing for the same context window in the same session.
Opus 4.7 has enough headroom to just keep track of all of it. Weaker models don’t. They cut corners — skip the profile, skip the falsification criterion, blind-flag-sweep instead of running a real hypothesis, hand back control mid-experiment.
Same lesson as Software 3.0 — it’s easy to get something working, hard to make it work reliably. And reliably means “with any reasonably capable model”, not just the strongest one you have access to.
The fix is to stop stuffing everything into one prompt and instead specialize the loop into a small number of purpose-built components. That’s what skills and sub-agents are for.
🧩 Formalizing the auto-optimization process using skills and sub-agents
Keeping everything in the same context might work, and the original prototype is proof that it can work. But agents don’t generally follow instructions precisely. There are a few practical examples:
- If you make an agent load a huge log from GKE into its main context window, it degrades the agent and it starts to care less about the original prompt instructions it was provided with. The solution would be spinning up a sub-agent to do the log parsing and only providing a minimal meaningful result back to the main agent thread.
- Whenever the agent is given a specific step to execute, like collecting a profile, for whatever reason it might decide to skip this step. The way to enforce it would be to make it write something concrete, like the profile URI it analyzed and a summary of that analysis.
- When you tell the agent to load information from the wiki, most likely it will do a sloppy job of it. Instead we can force it to load exactly the content we care about, and that should not be the whole wiki. We extract the domain-specific pages into a sub-wiki and force the agent to load just that.
In all cases this formalizes the process as a collection of skills and sub-agents.
Claude Code, Codex, and Antigravity all expose two extension mechanisms — skills and sub-agents — with slightly different names but essentially the same shape:
- A skill is a slash-command prompt loaded into the master’s context. It runs in the master’s tool-call space, sees everything the master sees, and its intermediate state accumulates in the master’s context window. Cheap and stateful. Good for decisions that need session state.
- A sub-agent is a separate conversation with its own context window. Its tool calls run in that isolated space; only a small summary comes back to the master. Expensive per invocation but the master’s context stays clean. Good for work that generates lots of intermediate state master doesn’t need.
The mental model I keep coming back to: skills share context, sub-agents isolate it. If the work needs the master to remember it, use a skill. If the work would burn 20k tokens of intermediate output that the master doesn’t need, use a sub-agent.
Both concepts translate across harnesses:
- Claude Code — skills / sub-agents
- Antigravity — skills / sub-agents
- Codex — skills / sub-agents
Once you can name components as one or the other, the fix for the Codex/Gemini reliability gap almost writes itself: split the monolithic loop prompt into a few skills and sub-agents, each with a single clear job.
🔄 Updated auto-optimization loop using skills and sub-agents
Instantiating this pattern for each stage of the loop turns the original monolithic prompt into a chain of specialized components:
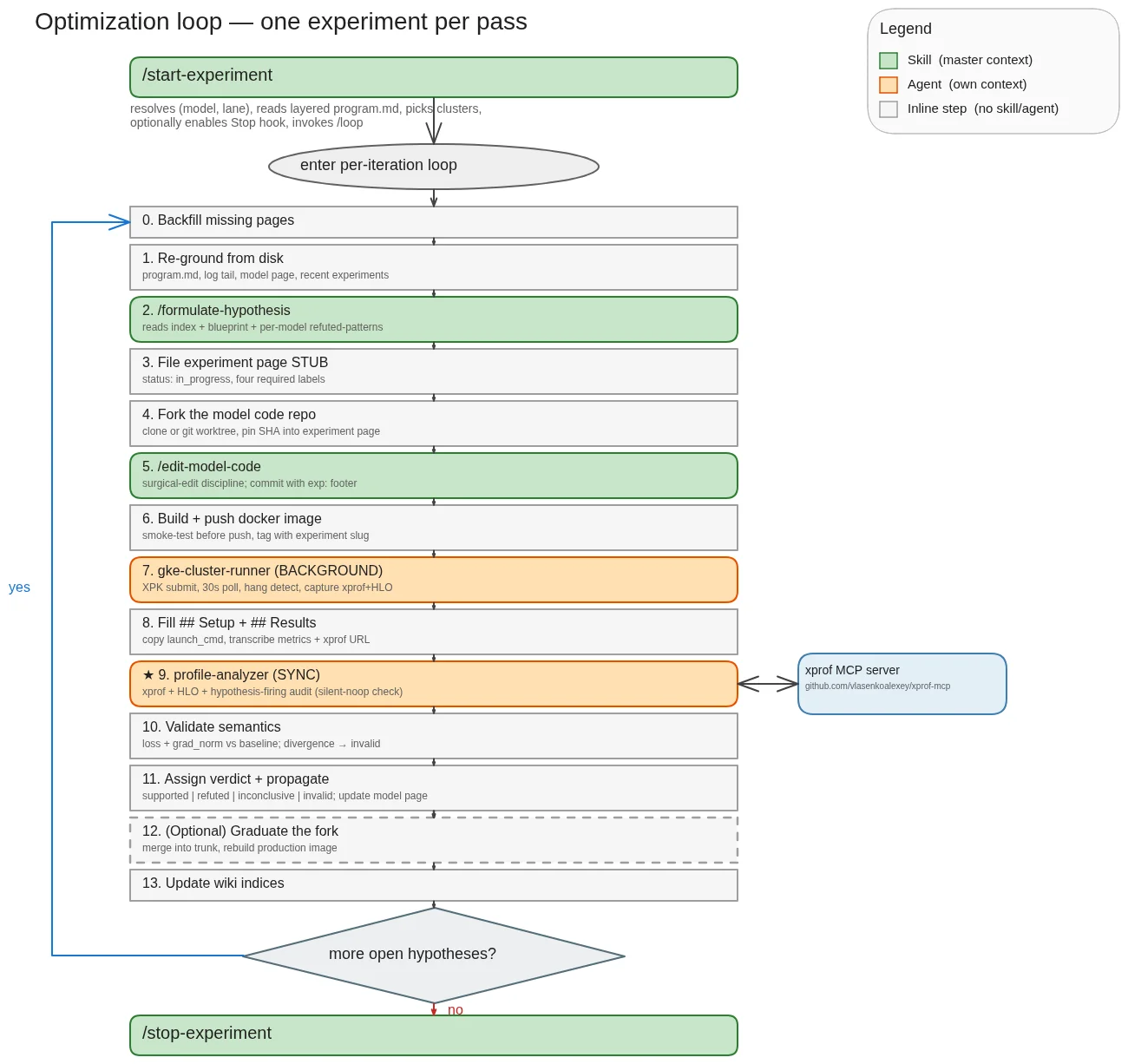 The user only interacts with
The user only interacts with /start-experiment and /stop-experiment. Between them, the master session drives a chain of specialized skills (green — decisions that stay in master’s context) and sub-agents (amber — work that runs in isolated context). One sub-agent — the profile analyzer — talks to the external xprof MCP server; the others read only their own sub-wiki slice.
The user doesn’t need to know or care about any of the internal steps — that’s the whole point. They call /start-experiment, walk away, and come back to a research trail. The specialization is a private detail of the loop.
Below is a detailed explanation for each of the core components of this optimization loop.
💡 /formulate-hypothesis — the central point of grounding
Every iteration starts with one decision: what to try next. /formulate-hypothesis produces that decision as a single, falsifiable proposal.
Without something like this, an autonomous loop tends to repeat refuted patterns. The agent has long-tail context, no memory of what was tried two days ago, and a strong bias toward whichever optimization technique is salient in the most recent profile. The skill compensates by forcibly loading three layers of knowledge from the wiki before proposing a candidate:
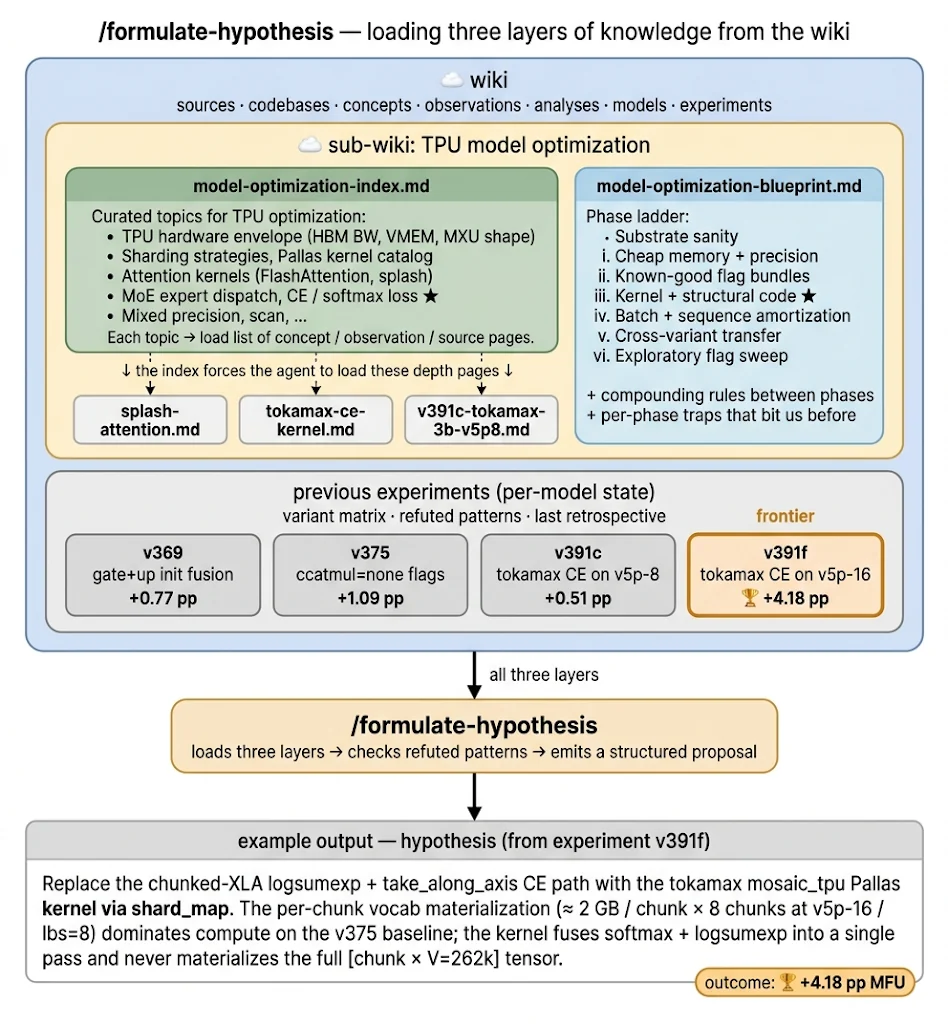 Optimization index (topics + pointers) + blueprint (ordered phases) + previous model state (recent experiments, refuted patterns) all get force-loaded before any hypothesis candidate is proposed.
Optimization index (topics + pointers) + blueprint (ordered phases) + previous model state (recent experiments, refuted patterns) all get force-loaded before any hypothesis candidate is proposed.
A domain-specific optimization index —
wiki/model-optimization-index.md. The wiki has grown to contain a lot of things; not all of it is optimization-specific. The index is a curated list of topics — TPU specs, sharding techniques, Pallas kernels, MoE dispatch, attention kernels, CE loss — with pointers to the specific concept/observation/source pages the agent should load for each topic. Regeneration prompt is right next to it, so the index itself gets rebuilt from the wiki as it grows.A generic optimization blueprint —
wiki/model-optimization-blueprint.md. While the index gives topics and pointers, the blueprint gives order: substrate sanity → cheap memory and precision → known-good flag bundles → kernel and structural code work → batch and sequence amortization → cross-variant transfer → exploratory flag sweeps. The blueprint is generated by an LLM abstracting learnings from prior experiments, and it can be regenerated from the experiment trail as new data lands.Previous model state — the last few experiments with verdicts, the most recent retrospective, and a per-model
refuted-patterns.mdlisting specific experiments that already refuted a pattern. Stored in the wiki under the model’s folder, accumulated as experiments land.
The output is a structured proposal: hypothesis, topic anchor in the index, blueprint phase and whether earlier phases are saturated, profile signal it targets, a falsification criterion, expected gain, effort estimate. It’s pattern-checked against the two refuted layers (generic principles + per-model experiments); any match abandons the candidate before dispatch. That single check is the largest safeguard against repeat-failure regressions.
This is a good example of a skill and not a sub-agent — the decision (what to try next) belongs to the master, and the loading of the sub-wiki plus the proposal itself is small enough to fit in master’s context.
✏️ /edit-model-code — the surgical-edit discipline
The original repo didn’t have a dedicated skill for editing model code. On Claude Code and Codex this was fine — both are strong at code. On Gemini it was obviously not fine — the model would rewrite whole files when a two-line diff was needed, and the next experiment would fail because unrelated code changed.
Andrej Karpathy published a small set of principles for LLM-driven coding that proved very effective as a prompt. The four rules are:
- Think Before Coding
- Simplicity First
- Surgical Changes
- Goal-Driven Execution
The prompt has been productionized and now has 180K GitHub stars, so it’s not niche. I adapted it into a /edit-model-code skill that gets invoked before opening any file in the per-experiment fork.
I didn’t run a proper before/after A/B, but the Antigravity/Gemini experiment failure rate from “wrong or overly aggressive code change” dropped visibly once the skill was in place.
🚀 gke-cluster-runner — a background sub-agent
The original setup ran XPK launches inline from the master session: xpk workload create, poll kubectl get jobset every 30 seconds, tail the worker-0 log, wait for the workload to finish. This worked for one experiment at a time, but had two structural problems.
The master’s context filled up with verbose XPK + kubectl output that contributed nothing to the next-iteration decision. And with multi-host workloads taking 10–60 minutes, the master couldn’t do anything else while one was running. For an autonomous loop expected to run for hours unattended, neither was acceptable.
An interesting finding along the way: no matter how many times you tell the agent to keep polling the workload, after some time it just ignores that. The polling reliability itself is a context-pollution victim.
Moving launch + poll + artifact capture into a dedicated gke-cluster-runner sub-agent solved both problems. The sub-agent runs in its own context, so the kubectl noise stays isolated from the master. It’s dispatched in background mode, so the master continues immediately and gets a callback when the sub-agent completes. It’s model-agnostic — the same sub-agent runs torchtitan + torch_tpu, JAX + MaxText, single-host + multi-host — without any per-model branching.
This is the canonical “use a sub-agent when…” case: the work is long, generates a large amount of intermediate state the master doesn’t need, runs in parallel with other tracks, and isolated failure matters — a 200-line traceback when a workload crashes shouldn’t take down the master.
📊 profile-analyzer — a sync sub-agent with a hypothesis-firing audit
The original loop did analyze profiles. The master read xprof traces and HLO dumps inline, identified dominant op buckets, computed regression diffs against prior baselines, and proposed where to look next.
The problem wasn’t that it didn’t analyze — it was that profile analysis is massively context-polluting. A single xprof trace is hundreds of MB. An HLO dump is thousands of files. The xprof MCP tool calls that walk them produce verbose op profiles, memory breakdowns, and per-module summaries. All of that landed in the master context, often consuming tens of thousands of tokens per experiment. Across a multi-hour loop, master spent most of its window remembering profile data instead of reasoning about what to try next.
Moving analysis into a profile-analyzer sub-agent solved the pollution problem. The sub-agent runs in its own context, exhausts whatever MCP tool calls it needs to reach a confident finding, and returns only synthesized markdown for the master to paste into the experiment page — two paste-ready sections: ## Profile (xprof bucket attribution, dominant ops, memory profile) and ## HLO Dump (module-level summary, fusion verification, regression diff vs the prior baseline). The sub-agent has its own sub-wiki — wiki/profile-analyzer-index.md — a pure-reference catalog for xprof + HLO + Pallas + TPU-device analysis, deliberately separated from the model-optimization index so nothing hypothesis-related bleeds in.
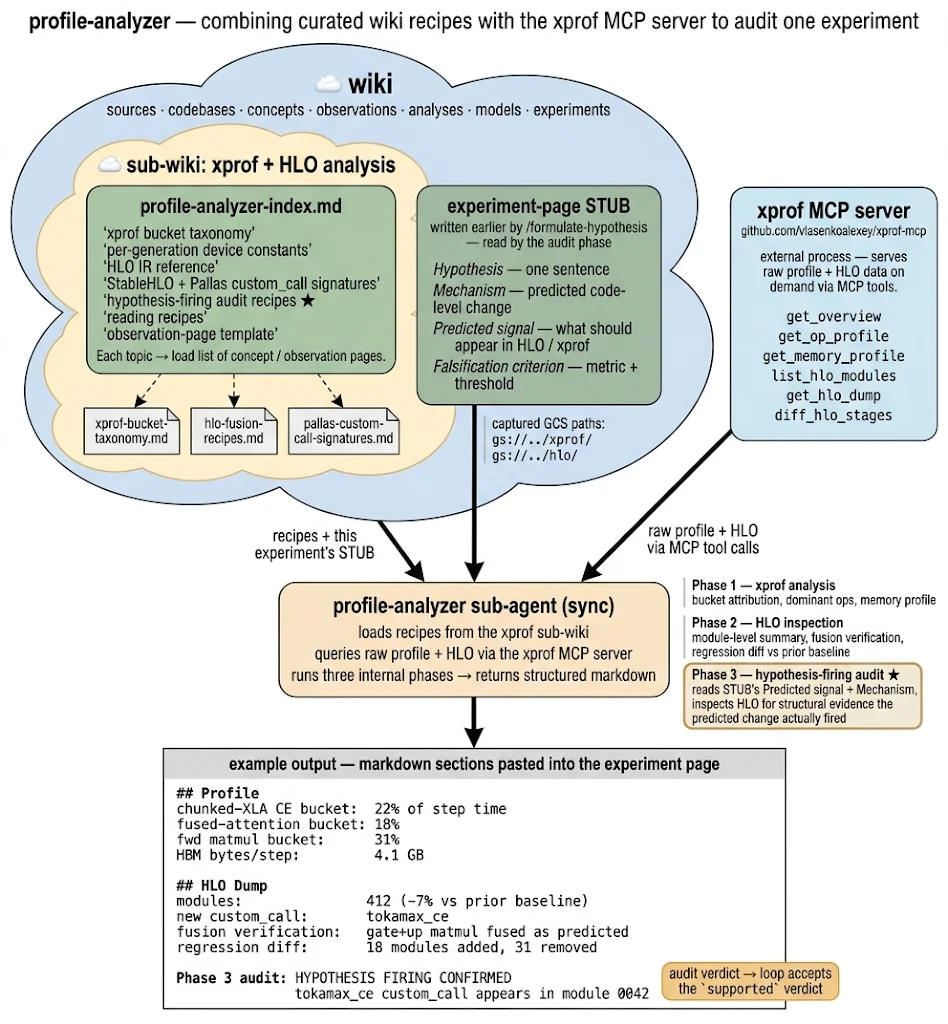 The profile-analyzer loads its own dedicated sub-wiki (xprof + HLO + Pallas reference), talks to the external xprof MCP server for live trace + HLO data, and returns two paste-ready markdown sections plus a Phase 3 hypothesis-firing audit line back to the master.
The profile-analyzer loads its own dedicated sub-wiki (xprof + HLO + Pallas reference), talks to the external xprof MCP server for live trace + HLO data, and returns two paste-ready markdown sections plus a Phase 3 hypothesis-firing audit line back to the master.
Unlike gke-cluster-runner, this one runs synchronously rather than in the background. The master can’t pick the next hypothesis without knowing where the time went on the current one and whether the predicted mechanism actually fired. Blocking on this is the right call — it’s typically 30 seconds to a couple of minutes of MCP tool-call work.
And there’s a third phase inside the sub-agent that ended up being surprisingly load-bearing: a hypothesis-firing audit. The sub-agent reads the ## Hypothesis under test section from the experiment page stub that /formulate-hypothesis wrote — specifically the Predicted signal and Mechanism labels — then inspects the HLO dump for structural evidence that the predicted mechanism actually fired.
If the hypothesis was “swap chunked-XLA CE for the tokamax mosaic_tpu kernel via shard_map”, the audit checks whether tokamax_ce actually appears as a custom_call in the HLO. If yes: HYPOTHESIS FIRING CONFIRMED. If no: SILENT NO-OP DETECTED, and the verdict is downgraded to inconclusive.
That single check catches a whole class of failure where the loop thinks it’s making progress but the compiler quietly optimized away the change, or the code path never fired, or the flag didn’t take effect. Before the audit, these silent no-ops would sometimes be filed as supported on the strength of a lucky noise sample. After the audit, they don’t get past dispatch.
🎓 Self-improvement — the loop feeding its own prompts
One benefit of running everything as an agentic loop is that the artifacts the loop produces — experiment pages, session logs — can be fed back into the loop’s own instructions to make it better next time. Two mechanisms here: one already in production, one still exploratory.
Concept extraction from the experiment trail. Every experiment the loop runs files a wiki page with hypothesis, verdict, and profile summary. The collection of supported experiments across a lane is a corpus of “what actually worked” — and an LLM can walk that corpus and pull out the recurring patterns. That’s exactly what wiki/model-optimization-blueprint.md is — the ordered phase ladder that /formulate-hypothesis loads on every iteration was extracted from prior experiments by another LLM, using a canned prompt sitting right next to it at model-optimization-blueprint-regenerate-prompt.md. As the wiki grows, I regenerate the blueprint; the loop then benefits from a better guide the next time it iterates.
Process optimization from the session log. Every loop iteration leaves a trail — which skills fired, which sub-agents got dispatched, where the master looped on the same refuted hypothesis, where it silently skipped a step. That log is itself an artifact an LLM can analyze, with the goal of improving the skill and sub-agent definitions themselves. One obvious conclusion is that different LLMs have different quirks — subjectively Codex seems to follow instruction better, Opus is most flexible and versatile, Gemini needs the surgical-edit discipline enforced harder — and could plausibly benefit from per-harness variants of the same skill. This is still exploratory; I haven’t productionized the meta-analysis path yet. But the raw material is on disk in every session directory, and nothing about the loop structure prevents it from becoming a normal input to the next round of regeneration.
📈 Comparing different LLMs/harnesses on updated auto-optimization loop
The Qwen3 8B experiment on v6e-8 was designed as the head-to-head test of the specialized loop. Same repo, same skills, same sub-agents, same wiki, same target hardware, same starting baseline. Only the harness + underlying model changed.
Setup. To give agents room to hillclimb on model performance, I needed to get them to a common starting point with a model that works but isn’t optimized. To do that I started from the PyTorch HuggingFace Qwen3-8B. First I told the agent to make this model work on TPU using torchax and set up profiling and logging necessary for the experiment. Then I told the agent to convert this model to JAX. As a result I got working Qwen3 with ~20% MFU and plenty of space to optimize it further.
Four harnesses. The exact same set of skills and sub-agents is exposed to each — Claude Code adapts them natively; Antigravity and Codex read them via the .agents/skills compatibility symlink that maps the .claude/ tree onto their respective conventions. Each harness gets the same one-line kickoff prompt — “/start-experiment for Qwen3 8B on v6e-8” — and is left unattended.
Results.
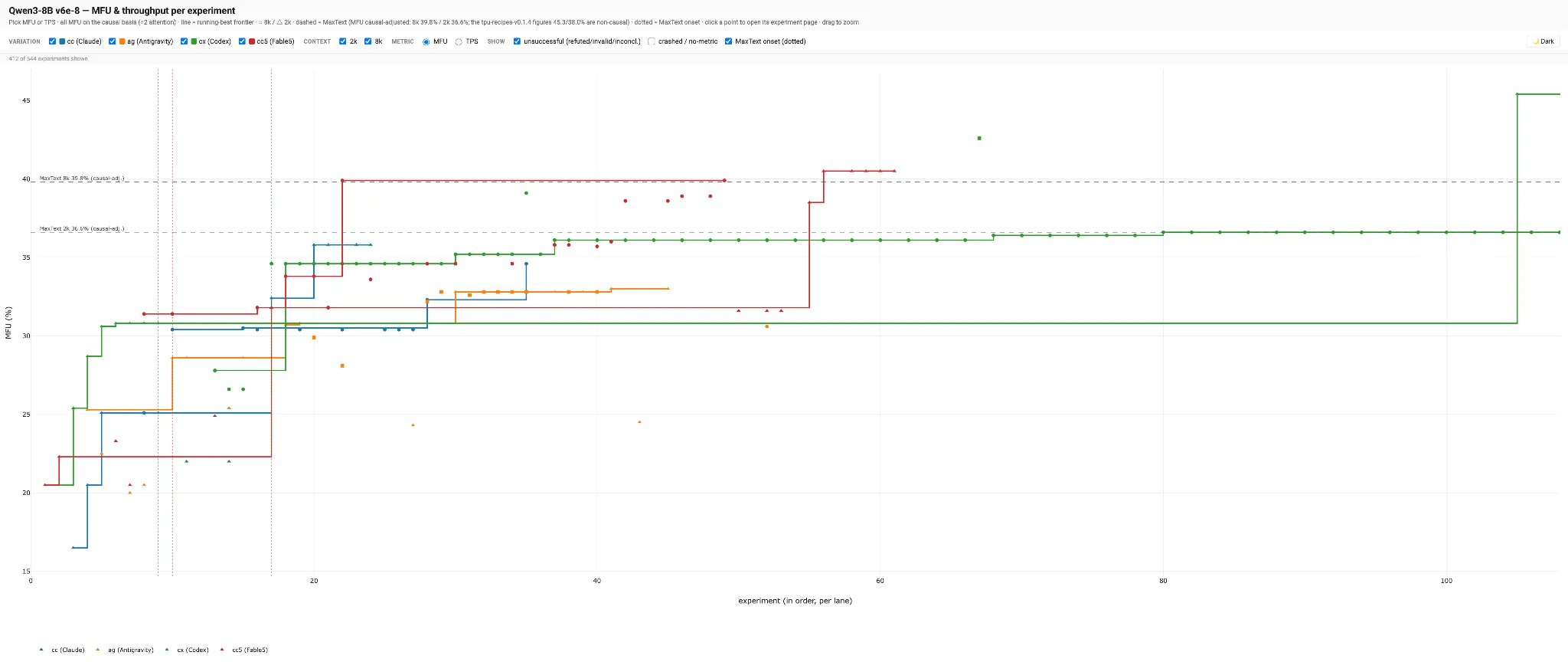 MFU trajectory over the unattended loop for each harness. Click through for the interactive per-harness explorer.
MFU trajectory over the unattended loop for each harness. Click through for the interactive per-harness explorer.
| Harness / model | Top MFU | Delta vs MaxText 39.8% | Loop behavior |
|---|---|---|---|
| Codex + GPT-5.5 | 43.2% | +8.5% | Ran cleanly end-to-end; the fewest silent no-ops caught by the audit. Aggressive on structural code changes. |
| Claude Code + Fable 5 | 39.9% | +0.3% | Fastest per-iteration wall clock. Good pattern recognition on profile analysis. |
| Claude Code + Opus 4.8 | 34.8% | −12.6% | Solid but conservative — favored flag sweeps over kernel work. |
| Antigravity + Gemini 3.1 Pro | 30.6% | −23.1% | Ran the loop end-to-end unattended for the first time. /edit-model-code was clearly load-bearing here. |
The point isn’t that Codex wins. The point is that four different agent + harness stacks each ran the same loop unattended, filed real experiment pages, converged on a coherent optimization trail, and produced a competitive number. The specialization into skills and sub-agents is what made that possible. Without it, only Claude Code + Opus 4.7 (from the first post) reliably got past hypothesis-formulation-and-selection stage.
🏁 Closing thoughts
The one-line story of these three posts is: LLM wiki + xprof MCP + autoresearch is a great starting point on a strong model; a few external guardrails make the loop reliable enough for unattended overnight runs; and specialization into skills and sub-agents makes it portable across harnesses.
The two axes of specialization that turned out to matter were:
- Skill vs sub-agent — do we want the intermediate work to accumulate in master’s context, or stay isolated?
- Sub-wiki scope — does this component read the whole wiki, or only its own specialized sub-domain slice?
The full framework — skills, sub-agents, wiki structure, all of it — is in the tpu_performance_autoresearch_wiki repo.